Prix Kaggle House ③ ~ Prévisions / Soumission ~
Prédisez les données de test et soumettez les fichiers de soumission en utilisant le modèle créé ci-dessous. Prix de la maison Kaggle② ~ Création d'un modèle ~
Charger la bibliothèque
import numpy as np
from sklearn.externals import joblib
Lire les données
def load_x_test() -> pd.DataFrame:
"""Lire la quantité de fonctionnalités des données de test créées à l'avance
:return:Caractéristiques des données de test
"""
return joblib.load('test_x.pkl')
def load_model(i_fold):
"""Chargez un modèle préfabriqué
:return:Modèle de pli cible
"""
return joblib.load(f'model-{i_fold}.pkl')
def load_pred_test():
"""Lire le résultat de la prédiction des données de test créées à l'avance
:return:Résultat prévu des données de test
"""
return joblib.load('pred-test.pkl')
Prédire les données de test
#Prédire les données de test en faisant la moyenne des modèles de chaque pli appris par validation croisée
test_x = load_x_test()
preds = []
n_fold = 4
#Faites des prédictions avec chaque modèle de pli
for i_fold in range(n_fold):
print(f'start prediction fold:{i_fold}')
model = load_model(i_fold)
pred = model.predict(test_x)
preds.append(pred)
print(f'end prediction fold:{i_fold}')
#Obtenez la valeur moyenne de la prévision
pred_avg = np.mean(preds, axis=0)
#Enregistrement des résultats de prédiction
joblib.dump(pred_avg, 'pred-test.pkl')
Créer un fichier de soumission pour soumission
pred = load_pred_test()
print(len(pred))
print(load_x_test())
submission = pd.DataFrame(pd.read_csv('test.csv')['Id'])
submission['SalePrice'] = np.exp(pred)
submission.to_csv(
'submission.csv',
index=False
)
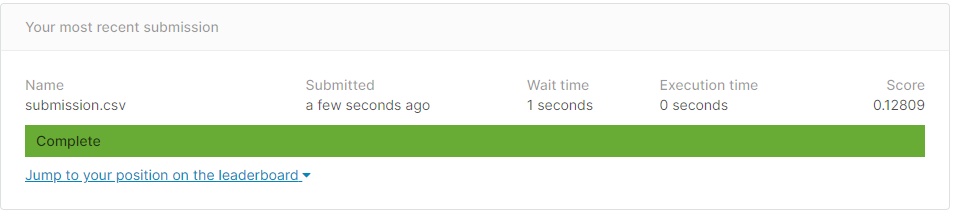
Résultat de la soumission
Recommended Posts