[Super Introduction to Machine Learning] Learn Pytorch tutorials
This is a compilation of what the author wrote instead of a memo, which the author has not yet grasped the whole picture. I will summarize the contents of the Pytorch tutorial + the contents examined in α. (I wrote ..., but it hardly conforms to the tutorial.)
With the goal of being able to use it freely, after deciding what you can understand, I will study with a policy of implementing it steadily.
This time is Chapter 2. Previous-> https://qiita.com/akaiteto/items/9ac0a84377600ed337a6
Introduction
Last time, I just looked at the processing of each layer of the neutral network, so This time, I will focus on optimization.
As a premise, I felt that it was a little confusing to just move the MNIST sample source, so As simple as possible, build an example from the position and actually move it, then From there, I will study with the goal of implementing various methods on my own.
Next, I will try to incorporate my own optimization method into the neutral network. In addition, what is implemented is just the steepest descent method. It may be helpful when implementing your own optimization techniques in your neutral network.
Network learning
Last misunderstanding
Last time, I presented the following calculation results in the explanation of the loss function.
It's very simple to do. First, enter the applicable input data into the defined network, and then I got the output value (data containing the feature information).
After that, do the same for various other input data, The "error" with the output location calculated first was calculated, and it was output as "evaluation".
#Execution result
*****Learning phase*****
Input data for network learning
tensor([[[[0., 1., 0., 1.],
[0., 0., 0., 0.],
[0., 1., 0., 1.],
[0., 0., 0., 0.]]]])
*****Evaluation phase*****
Enter the same data
input:
tensor([[[[0., 1., 0., 1.],
[0., 0., 0., 0.],
[0., 1., 0., 1.],
[0., 0., 0., 0.]]]])
Rating tensor(0., grad_fn=<MseLossBackward>)
Enter slightly different data
input:
tensor([[[[0., 2., 0., 2.],
[0., 0., 0., 0.],
[0., 2., 0., 2.],
[0., 0., 0., 0.]]]])
Rating tensor(0.4581, grad_fn=<MseLossBackward>)
Enter completely different data
input:
tensor([[[[ 10., 122., 10., 122.],
[1000., 200., 1000., 200.],
[ 10., 122., 10., 122.],
[1000., 200., 1000., 200.]]]])
Rating tensor(58437.6680, grad_fn=<MseLossBackward>)
"I'm sure this evaluation value will be judged by the threshold value to see if it is the same." I thought at that time. Is it considered as different data if it is separated by 0.5 or more? It is about recognition.
The output value is, so to speak, a numerical value extracted from the characteristics of each data. So CNN is for seeing how close the features are! When.
... but this isn't enough to do. As it is now, it's just filtered. I didn't understand learning correctly.
Correct answer data A
tensor([[[[0., 2., 0., 2.],
[0., 0., 0., 0.],
[0., 2., 0., 2.],
[0., 0., 0., 0.]]]])
Input data B
tensor([[[[0., 1., 0., 1.],
[0., 0., 0., 0.],
[0., 1., 0., 1.],
[0., 0., 0., 0.]]]])
Rating tensor(0.4581, grad_fn=<MseLossBackward>)
The essence of the learning phase is
"Input data A and B, which are slightly different but actually point to the same thing, Let's recognize it as the same thing! !! "about it.
Rating tensor(0.4581, grad_fn=<MseLossBackward>)
This number output as an error. This numerical value shows how much the input data A and B are out of alignment.
There is an error in the numerical value, but in reality A and B are the same, so The error should ideally be "0".
That is, what is the essence of learning? Large error between input data A and B, output as "0.4581" This is the essence of "adding a small hand" so that it is output as "0" as much as possible.
By adjusting the "weight" of each layer of the network so that the error is output as 0, The essence is to "learn" that "there is no error-A and B are the same".
Try to optimize
Optimization (stop thinking)
What kind of calculation formula is used to adjust the weight? ... I'll put it aside, and first stop thinking and let it learn with pytorch.
I don't know why, and I don't want to use various cool layers in the MNIST example, so Let's test with a simpler example as far as we understand.
Pattern A
tensor([[[[0., 1., 0., 1.],
[0., 1., 0., 1.],
[0., 1., 0., 1.],
[0., 1., 0., 1.]]]])
Pattern B
tensor([[[[1., 1., 1., 1.],
[0., 1., 0., 1.],
[0., 1., 0., 1.],
[1., 1., 1., 1.]]]])
Let's learn and test the above two patterns.
The entire
test.py
import torch.nn as nn
import torch.nn.functional as F
import torch
from torch import optim
import matplotlib.pyplot as plt
import numpy as np
class DataType():
TypeA = "TypeA"
TypeA_idx = 0
TypeB = "TypeB"
TypeB_idx = 1
TypeOther_idx = 1
def outputData_TypeA(i):
npData = np.array([[0,i,0,i],
[0,i,0,i],
[0,i,0,i],
[0,i,0,i]])
tor_data = torch.from_numpy(np.array(npData).reshape(1, 1, 4, 4).astype(np.float32)).clone()
return tor_data
def outputData_TypeB(i):
npData = np.array([[i,i,i,i],
[0,i,0,i],
[0,i,0,i],
[i,i,i,i]])
tor_data = torch.from_numpy(np.array(npData).reshape(1, 1, 4, 4).astype(np.float32)).clone()
return tor_data
class Test_Conv(nn.Module):
kernel_filter = None
def __init__(self):
super(Test_Conv, self).__init__()
ksize = 4
self.conv = nn.Conv2d(
in_channels=1,
out_channels=4,
kernel_size=4,
bias=False)
def forward(self, x):
x = self.conv(x)
x = x.view(1,4)
return x
#Data preparation during test
input_data = []
strData = "data"
strLabel = "type"
for i in range(20):
input_data.append({strData:outputData_TypeA(i),strLabel:DataType.TypeA})
for i in range(20):
input_data.append({strData:outputData_TypeB(i),strLabel:DataType.TypeB})
print("Prepare a total of 200 test data of the following patterns")
print("Pattern A")
print(outputData_TypeA(1))
print("Pattern B")
print(outputData_TypeB(1))
print("Make sure that these two patterns can be distinguished.")
print("\n\n")
#Network definition
Test_Conv = Test_Conv()
#input
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(Test_Conv.parameters(), lr=0.001, momentum=0.9)
print("***Try before learning***")
##Try to put appropriate data in the learned model.
NG_data = outputData_TypeA(999999999)
answer_data = [DataType.TypeA_idx]
answer_data = torch.from_numpy(np.array(answer_data).reshape(1).astype(np.int64)).clone()
print("\n\n")
outputs = Test_Conv(NG_data)
_, predicted = torch.max(outputs.data, 1)
correct = (answer_data == predicted).sum().item()
print("Correct answer rate: {} %".format(correct / len(predicted) * 100.0))
print("***Learning phase***")
epochs = 2
for i in range(epochs):
for dicData in input_data:
#Preparation of training data
train_data = dicData[strData]
#Preparation of correct answer data
answer_data = []
label = dicData[strLabel]
if label == DataType.TypeA:
answer_data = [DataType.TypeA_idx]
elif label == DataType.TypeB:
answer_data = [DataType.TypeB_idx]
else:
answer_data = [DataType.TypeOther_idx]
answer_data = torch.from_numpy(np.array(answer_data).reshape(1).astype(np.int64)).clone()
#Optimization process
optimizer.zero_grad()
outputs = Test_Conv(train_data)
loss = criterion(outputs, answer_data)
# print(train_data.shape)
# print(outputs.shape)
# print(answer_data.shape)
#
# exit()
loss.backward()
optimizer.step()
print("\t", i, " :error= ",loss.item())
print("\n\n")
print("***Test phase***")
##Try to put appropriate data in the learned model.
input_data = outputData_TypeA(999999999)
answer_data = [DataType.TypeA_idx]
answer_data = torch.from_numpy(np.array(answer_data).reshape(1).astype(np.int64)).clone()
outputs = Test_Conv(input_data)
_, predicted = torch.max(outputs.data, 1)
correct = (answer_data == predicted).sum().item()
print("Correct answer rate: {} %".format(correct / len(predicted) * 100.0))
exit()
Prepare a total of 200 test data of the following patterns
Pattern A
tensor([[[[0., 1., 0., 1.],
[0., 1., 0., 1.],
[0., 1., 0., 1.],
[0., 1., 0., 1.]]]])
Pattern B
tensor([[[[1., 1., 1., 1.],
[0., 1., 0., 1.],
[0., 1., 0., 1.],
[1., 1., 1., 1.]]]])
Make sure that these two patterns can be distinguished.
***Try before learning***
Correct answer rate: 0.0 %
***Learning phase***
0 :error= 1.3862943649291992
0 :error= 1.893149733543396
0 :error= 2.4831488132476807
0 :error= 3.0793371200561523
0 :error= 3.550563335418701
0 :error= 3.7199602127075195
0 :error= 3.3844733238220215
0 :error= 2.374782085418701
0 :error= 0.8799697160720825
0 :error= 0.09877146035432816
0 :error= 0.006193255074322224
0 :error= 0.00034528967808000743
0 :error= 1.8000440832111053e-05
0 :error= 8.344646857949556e-07
0 :error= 0.0
0 :error= 0.0
0 :error= 0.0
0 :error= 0.0
0 :error= 0.0
0 :error= 0.0
0 :error= 0.0
0 :error= 0.0
0 :error= 0.0
.
.
.
***Test phase***
Correct answer rate: 100.0 %
It's a simple source, but let's look at it one by one.
Network definition
test.py
class Test_Conv(nn.Module):
kernel_filter = None
def __init__(self):
super(Test_Conv, self).__init__()
ksize = 4
self.conv = nn.Conv2d(
in_channels=1,
out_channels=4,
kernel_size=4,
bias=False)
def forward(self, x):
x = self.conv(x)
x = x.view(1,4)
return x
In MNIST, all the data was input at once as input data. However, that would make it too large to be intuitively understood, so It is set to insert monochrome images one by one.
Since the convolutional layer $ out_channels = 4 $, four features are extracted with a filter, $ x.view $ is dimensioned for comparison with the correct label.
Try to apply before learning
test.py
print("***Try before learning***")
##Try to put appropriate data in the learned model.
NG_data = outputData_TypeA(999999999)
answer_data = [DataType.TypeA_idx]
answer_data = torch.from_numpy(np.array(answer_data).reshape(1).astype(np.int64)).clone()
print("\n\n")
outputs = Test_Conv(NG_data)
_, predicted = torch.max(outputs.data, 1)
correct = (answer_data == predicted).sum().item()
print("Correct answer rate: {} %".format(correct / len(predicted) * 100.0))
I will try it before learning. The code is different, but it is a reproduction of the "last misunderstanding". Sure enough, the correct answer rate is 0%.
Network learning
test.py
#Preparation of training data
train_data = dicData[strData]
#Preparation of correct answer data
answer_data = []
label = dicData[strLabel]
if label == DataType.TypeA:
answer_data = [DataType.TypeA_idx]
elif label == DataType.TypeB:
answer_data = [DataType.TypeB_idx]
else:
answer_data = [DataType.TypeOther_idx]
answer_data = torch.from_numpy(np.array(answer_data).reshape(1).astype(np.int64)).clone()
#Optimization process
optimizer.zero_grad()
outputs = Test_Conv(train_data)
loss = criterion(outputs, answer_data)
loss.backward()
optimizer.step()
print("\t", i, " :error= ",loss.item())
In the section "Last Misunderstanding", I wrote as follows
Large error between input data A and B, "0".What is output as "4581"
The essence is to "add a small hand" so that the output is infinitely "0".
Network learning does this. At the beginning of the process, first put only one data of either pattern A or pattern B in $ train_data $.
test.py
outputs = Test_Conv(train_data)
Inside the network, 4 features are calculated by applying 4 filters, Outputs data that includes four features per "one" data. In terms of dimensions, it is the data of [1,4].
Next, prepare the correct answer data.
answer_data = torch.from_numpy(np.array(answer_data).reshape(1).astype(np.int64)).clone()
Set the correct answer for the output "one data". Since the character string cannot be set, if it is pattern A data, "0", If it is B of pattern B, set it to "1". Since it is the correct answer data for one data, the dimension of the correct answer data is the data of [1].
Dimensional image
#This example
[Output data structure]
-data
-First feature
-Second feature
-Third feature
-Fourth feature
[Correct data structure]
-Answer to the data(1?0?)
test.py
loss = criterion(outputs, answer_data)
Then calculate the error. Since the weight is adjusted for each correct label, include the correct label as well.
optimizer.step()
Then, it executes a new process called optimization, which has not yet appeared. In the for loop, input the output data for each type A and type B, I think that the weight is adjusted so that the error in each type approaches 0. (Since it is in the thinking stop phase now, I will study later what kind of adjustments are being made!)
What is optimization? As with wikipedia, finding the optimal state of a program is called optimization. Here, the optimization is performed by calculating where the error is minimized.
Execution result
Let's see the execution result.
***Test phase***
Correct answer rate: 100.0 %
Yes, it's 100%. What was 0% before learning was able to learn safely.
Optimization (implemented by yourself)
The heart of the process is the optimization process performed by $ optimizer.step () $. There are many optimization methods that can be used with pytorch, and this time I chose SGD (stochastic gradient descent).
Looking back on the optimization process performed so far, I'm just using a function already implemented in pytorch and I'm not doing anything.
When you want to implement some optimization method in your dissertation What should I do specifically?
... so First, we will implement a simple optimization method called "Sudden Descent Method (GD)" as an example. First of all, the steepest descent method is not practical. The times are going backwards from the SGD used this time. However, I feel that it is suitable for studying, so Let's implement the steepest descent method.
Image of optimization
What do you do with optimization? In order to give an intuitive image, let's express it in a simple formula. (I haven't read any papers at the time of making this. Since it is an image, I made a mistake in a strict sense. Just for reference ...)
y = f(x)
When I put the input data in the network, the feature value came back as a numerical value. In other words, if you enter the input data $ x $, $ y $ will be returned as the output. Let this be $ y = f (x) $.
gosa = |f(A)-f(B)|
And when the input data $ A $ and $ B $ are given to this formula, I want to adjust so that the difference is the minimum value. Since A and B are actually the same data, we want to get the same output result.
gosa(weight) = |g(A)-g(B)|\\
g(x) = weight * f(x)
Now introduce the parameter $ weight $. We give weights to $ f (x) $, which is a network function. The problem of wanting to minimize the error by introducing this formula is It replaces finding the parameter $ weight $ that can minimize the error.
All you have to do is find the $ weight $ that minimizes $ gosa (weight) $.
Optimize with a simple graph
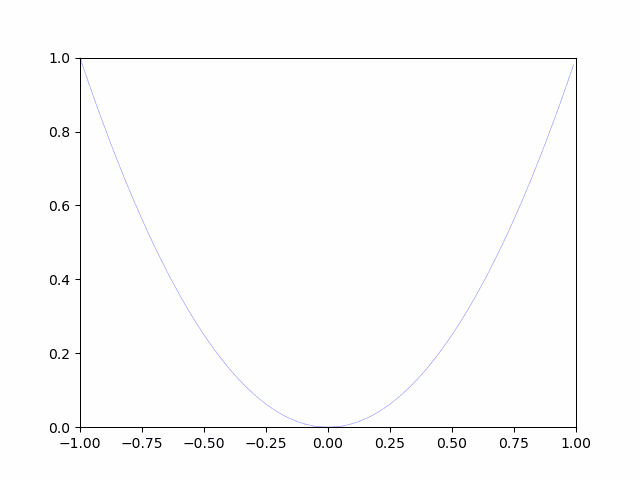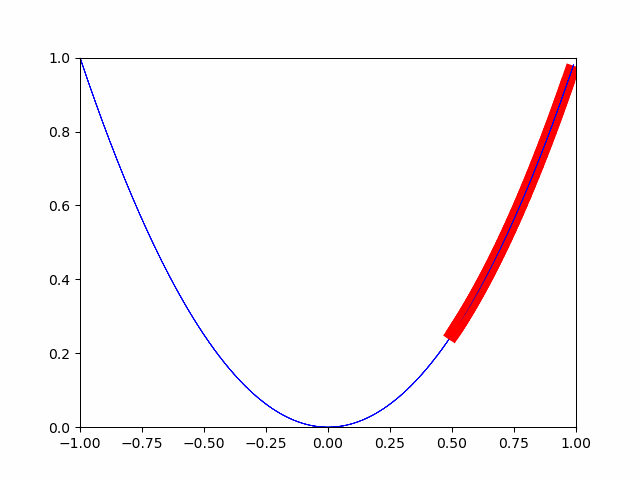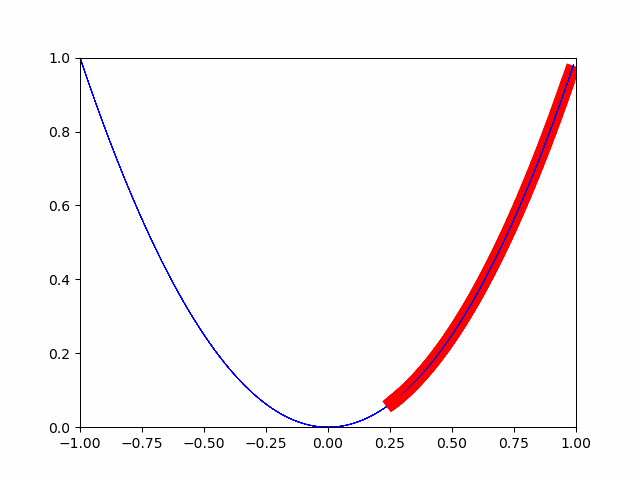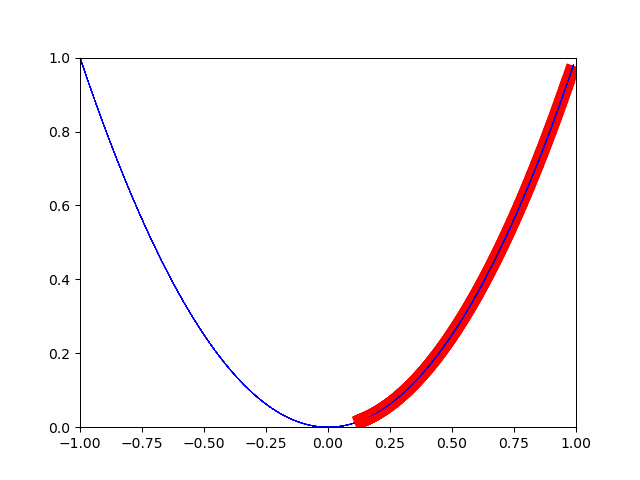
Let's optimize with a simple formula. Speaking of minimization problems, I did the $ y = x ^ 2 $ problem when I was in junior high school. At that time, the minimum value was calculated using a very limited formula, assuming manual calculation.
Here, assuming that $ y = x ^ 2 $ is $ gosa (weight) $, Let's solve it with an optimization method called the steepest descent method.
y = x^2\\
\frac{d}{dy}
=
2x
The derivative $ \ frac {d} {dy} $ of $ y = x ^ 2 $ is as above. The graph $ y = x ^ 2 $ is a graph that gradually changes in the smallest unit of $ \ frac {d} {dy} $.
The steepest descent method is to gradually move by a small change. This is a method that considers the point where the minute change is completely 0 to be the minimum value. (When I was in junior high school, there was a problem that the point where the slope became 0 was the minimum and maximum.)
So, let's try using pytorch's automatic differentiation function.
As you can see in the image, it is gradually approaching the minimum value. In this way, the optimization is done for the minimum value.
Below, the source.
test.py
if __name__ == '__main__':
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
import numpy as np
import torch
import torchvision
import torchvision.transforms as transforms
def func(x):
return x[0] ** 2
fig, ax = plt.subplots()
artists = []
im, = ax.plot([], [])
#Graph range
ax.set_xlim(-1.0, 1.0)
ax.set_ylim(0.0, 1.0)
# f = x*For definition of x
F_main = np.arange(-1.0, 1.0, 0.01)
n_epoch = 800 #Number of learning
eta = 0.01 #Step width
x_arr = []
f_arr = []
x_tor = torch.tensor([1.0], requires_grad=True)
for epoch in range(n_epoch):
#Definition of function to optimize
f = func(x_tor)
# x_Calculate the gradient at the tor point
f.backward()
with torch.no_grad():
# 1.Gradient method
# x_Subtract the minute changes from tor little by little,
#Gradually approach the minimum value
x_tor = x_tor - eta * x_tor.grad
# 2.This is the processing for animation
f = x_tor[0] ** 2
x_arr.append(float(x_tor[0]))
f_arr.append(float(f))
x_tor.requires_grad = True
def update_anim(frame):
#Processing to save gif
#After executing FuncAnimation, it is automatically and repeatedly executed.(frame =Number of frames)
ims = []
if frame == 0:
y = f_arr[frame]
x = x_arr[frame]
else:
y = [f_arr[frame-1],f_arr[frame]]
x = [x_arr[frame-1],x_arr[frame]]
ims.append(ax.plot(F_main ,F_main*F_main,color="b",alpha=0.2,lw=0.5))
ims.append(ax.plot(x ,y,lw=10,color="r"))
# im.set_data(x, y)
return ims
anim = FuncAnimation(fig, update_anim, blit=False,interval=50)
anim.save('GD_pattern 1.gif', writer="pillow")
exit()
Implementation of optimization (steepest descent method)
I will implement it. The purpose of this section is not to implement the steepest descent method itself. This is a verification to confirm that "Implement your own optimization function in this way".
Also, what is written in a long way, so I will write only the main points.
test.py
optimizer = optim.SGD(Test_Conv.parameters(), lr=0.001, momentum=0.9)
In pytorch, you can choose various optimization methods from optim. Implementations of each technique are created by inheriting a class called $ torch.optim.Optimizer $. On the flip side, you can easily create your own inherited class for $ torch.optim.Optimizer $. So, as before, optimize for $ y = x ^ 2 $.
This example doesn't use a neutral network, If I define $ SimpleGD $ in the same way, it can still be used in a neutral network.
↓ ↓ ↓ Overall source ↓ ↓ ↓
test.py
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
import numpy as np
import torch
import torchvision
import torchvision.transforms as transforms
class SimpleGD(torch.optim.Optimizer):
def __init__(self, params, lr):
defaults = dict(lr=lr)
super(SimpleGD, self).__init__(params, defaults)
@torch.no_grad()
def step(self, closure=None):
loss = None
if closure is not None:
with torch.enable_grad():
loss = closure()
for group in self.param_groups:
for p in group['params']:
if p.grad is None:
continue
d_p = p.grad
#Addition of tensor
# p = p - d/dp(Small changes) * lr
# (lr is multiplied because the range of change is too small if it is only a small change)
p.add_(d_p*-group['lr'])
return loss
def func(x):
return x[0] ** 2
fig, ax = plt.subplots()
artists = []
im, = ax.plot([], [])
#Graph range
ax.set_xlim(-1.0, 1.0)
ax.set_ylim(0.0, 1.0)
# f = x*For definition of x
F_main = np.arange(-1.0, 1.0, 0.01)
n_epoch = 50 #Number of learning
eta = 0.01 #Step width
x_tor = torch.tensor([1.0], requires_grad=True)
param=[x_tor]
optimizer = SimpleGD(param, lr=0.1)
for epoch in range(n_epoch):
optimizer.zero_grad()
#Definition of function to optimize
f = func(x_tor)
# x_Calculate the gradient at the tor point
f.backward()
optimizer.step()
x_tor.requires_grad = True
#Gradually y=x*Minimum value of x=0.Going to 0
# print(x_tor)
exit()
Of these, the most important This is the "class Simple GD" part that declares your own optimization function.
test.py
class SimpleGD(torch.optim.Optimizer):
def __init__(self, params, lr):
defaults = dict(lr=lr)
super(SimpleGD, self).__init__(params, defaults)
@torch.no_grad()
def step(self, closure=None):
loss = None
if closure is not None:
with torch.enable_grad():
loss = closure()
for group in self.param_groups:
for p in group['params']:
if p.grad is None:
continue
d_p = p.grad
#Addition of tensor
# p = p - d/dp(Small changes) * lr
# (lr is multiplied because the range of change is too small if it is only a small change)
p.add_(d_p*-group['lr'])
return loss
Let's take a closer look. First, about the init part.
test.py
def __init__(self, params, lr):
defaults = dict(lr=lr)
super(SimpleGD, self).__init__(params, defaults)
lr is when subtracting minute changes If it is only a small change, the range of change is too small or too large, so The parameters to be applied to minute changes are specified.
SimpleGD required lr, so I declared it here. If you need other things, add them to the init argument and add the declaration firmly in the dict.
test.py
@torch.no_grad()
def step(self, closure=None):
torch.optim.Optimizer This function must be declared when inheriting the class. Optimization is done by calling this function during training.
self.param_groups are the params you passed when you created the SimpleGD instance. If the gradient (small change) has already been calculated with backward (), you can also get the gradient from here.
test.py
d_p = p.grad
#Addition of tensor
# p = p - d/dp(Small changes) * lr
# (lr is multiplied because the range of change is too small if it is only a small change)
p.add_(d_p*-group['lr'])
Get p.grad, that is, minute changes, The minute change is reflected in p = tensor. By this operation, the parameters gradually move toward the minimum value.
・ ・ ・ ・ Since the steepest descent method only subtracts a minute amount, it easily falls into a local solution. Local solution. Imagine a graph with lots of bumps like $ y = x ^ 2 $. Since the steepest descent method considers the place where the slope becomes 0 as the minimum value, Whenever it reaches any of the tips of this convex, it will be regarded as an extremum.
From this, it can be said that this method is not robust for any data.
in conclusion
In Chapters 1 and 2, I got a little overview of the network.
As for the schedule after the next time, Studying point cloud machine learning that I wanted to study the most, I will study PointNet in particular.
After that, I will study RNN, autoencoder, GAN, and DQN.
Recommended Posts