I tried Value Iteration Networks
It is the 12th day of Chainer Advent Calendar 2016.
~~ Currently, at 6 pm on the 11th, it will take another 14 hours if the implementation is finally completed and learning is started on AWS \ (^ o ^) / ~~
NEW code has been released! (Note: I've refactored it a lot, so I'm sorry if it doesn't work. I'm planning to check the operation after a while. I'm sorry I don't have the document.) https://github.com/peisuke/vin
About the article
In this article, I will write a commentary on the paper that won the Best Paper Award at NIPS 2016 (last week!), Which is a top-conference of machine learning, and the result of implementing it in Chainer.
~~ However, I started reading the dissertation after I knew that I had won the Award, so I had a last-minute schedule as shown above, and the experimental results have not yet come out ... So, add more content to your dissertation ... Also, although it will be a little late, I will definitely post the experimental results, maybe. ~~ I managed to post the experimental results!
background
The problem dealt with in the paper is to set the start and goal on the map and find the shortest path when the robot moves in the environment as shown in the figure below. Of course, such problems have been around for a long time, but past research requires the assumption that the environment and robot models are known. Actually, it is not possible to completely describe a robot model, so the aim is to be able to search for a route without modeling by learning that area.

When the robot operates in the environment, the next action must be taken in consideration of future environmental changes. Value Iteration is the process of adding the reward value of the current state (achieved the purpose, approaching the goal, etc.) and the reward value of the next state that temporarily advanced the operation by one step. By repeating it, you can find out how good the current state of the robot is in the future and how to move next.
However, it is not easy to pre-calculate the true reward value of the current state. This is because you only get the reward value when you reach the goal, so you need to calculate all the steps to reach the goal. It can be achieved by perfectly simulating all changes in the environment, robot models, etc., and by executing a large amount of calculation processing, but this is possible in very few cases. Therefore, it is thought that the above simulations and a large amount of calculations can be avoided by learning appropriate future rewards for the situation using deep learning, and various methods have been studied.
One of the most famous methods is Deep Q-Network. This uses a method called reinforcement learning, in which the robot itself makes mistakes in performing actions in the environment and remembers what kind of action should be taken in what situation. However, since Deep Q-Network makes mistakes in implementing the given environment, there is a problem that the learning results cannot be diverted when the environment changes. In addition, it may be possible to solve it by spreading the enforcement error to another environment. It is possible that this is the case, but it was reported in this paper that the accuracy did not improve through experiments. Now, as another means, there is Imitation Learning (learning by imitation). This is to learn the action to be taken by directly imitating the action of the expert without making a mistake in enforcement. Learning will be easier because you don't have to make extra enforcement mistakes. On the other hand, there remains the problem that it cannot be applied well to changes in the environment.
In the first place, it is quite necessary to predict the surroundings appropriately in the absence of information to decide the movement based on learning in anticipation of the future regardless of the new environment without manually giving a model of the robot or environment. It's difficult. If such a thing can be done, a robot that can read and operate the air without learning and programming can be realized.
** It seems that it has been done. ** **
That's why. read. Aviv Tamar, Yi Wu, Garrett Thomas, Sergey Levine, and Pieter Abbeel, "Value Iteration Networks", NIPS 2016. And the author is also such a face, S. Levine, and P. Abbeel
About Value Iteration Networks
I'm sorry, the introduction has become longer. This research was disappointing because I also tried and failed. By the way, the Value Iteration Network is simply (1) to estimate the reward from the input state by CNN, (2) to propagate the reward to the weight sharing CNN according to the action taken by itself, and (3) to estimate. The structure is such that only the reward at the position of interest is cut out, and (4) the operation is determined by full connection. The formula is difficult to write, so I will omit it.

In the above figure in the paper, the observation $ \ phi (s) $ multiplies the input image by CNN, and puts this in the estimated reward $ \ bar {R} $. In addition, $ \ bar {P} $ is a conversion of how the state changes when the action $ a $ is given to the state $ s $, but in this problem, the state change is ignored as known. .. The VI module calculates how much reward you will accumulate if you move from a given estimated reward map, which will be described later. The "Attention" in the next frame is the cutout part of which side of the image to focus on. In ordinary deep learning, it is often connected from the entire screen to the FC layer, but it is difficult because the parameters increase. On the other hand, if you know which side of the screen is filled with the information you want, you can easily calculate by targeting only that area. In this case, the reward information for determining the next movement direction is added to the robot's own position, so the robot's position $ s $ is targeted. Finally, the reward information is connected to the behavior information using the FC layer. As a result, we know which action to take (right, left, up, down, etc.), so softmax cross entropy compares it with the true direction of travel and calculates the inverse error propagation.
Now, the VI module looks like this:

First, we convolve the reward $ \ bar {R} $ given as input to calculate $ \ bar {Q} $. $ \ bar {Q} $ calculates how much the robot is rewarded for the motion $ a $ when the robot selects the motion $ a $, together with the current reward. Finally, by taking the MAX on a channel-by-channel basis, you get the reward $ \ bar {V} $ for the best behaviour. By calculating the VI module again based on this reward, the reward can be propagated in sequence.
Implementation
Now that we've covered the whole thing, let's move on to the implementation. This paper consists of separate programs for data preparation, learning, and result display. Only the learning and prediction parts are described here. ~~ I will upload it to github soon. ~~ Uploaded.
First of all, about network initialization.
class VIN(chainer.Chain):
def __init__(self, k = 10, l_h=150, l_q=10, l_a=8):
super(VIN, self).__init__(
conv1=L.Convolution2D(2, l_h, 3, stride=1, pad=1),
conv2=L.Convolution2D(l_h, 1, 1, stride=1, pad=0, nobias=True),
conv3=L.Convolution2D(1, l_q, 3, stride=1, pad=1, nobias=True),
conv3b=L.Convolution2D(1, l_q, 3, stride=1, pad=1, nobias=True),
l3=L.Linear(l_q, l_a, nobias=True),
)
self.k = k
self.train = True
conv1 and conv2 are the weights of conversion from map data to estimated reward. The input is two-dimensional, the image that describes the obstacle on the map is assigned to channel 1, and the image that describes the goal position is assigned to channel 2. The output is the reward value at each position on the map and is one-dimensional. conv3 is the weight for converting from the reward value, and conv3b is the weight for converting the reward value propagated by the VI to the predicted reward value corresponding to the position x movement. l3 is the weight obtained by Attention to convert the future predicted reward value at the robot position into the final movement. Next, the network is listed below.
def __call__(self, x, s1, s2):
h = self.relu(self.conv1(x))
r = self.conv2(h)
q = self.conv3(r)
v = F.max(q, axis=1, keepdims=True)
for i in xrange(self.k - 1):
q = self.conv3(r) + self.conv3b(v)
v = F.max(q, axis=1, keepdims=True)
q = self.conv3(r) + self.conv3b(v)
t = s2 * q.data.shape[3] + s1
q = F.reshape(q, (q.data.shape[0], q.data.shape[1], -1))
q = F.rollaxis(q, 2, 1)
t_data_cpu = chainer.cuda.to_cpu(t.data)
w = np.zeros(q.data.shape, dtype=np.float32)
w[six.moves.range(t_data_cpu.size), t_data_cpu] = 1.0
if isinstance(q.data, chainer.cuda.ndarray):
w = chainer.cuda.to_gpu(w)
w = chainer.Variable(w, volatile=not self.train)
q_out = F.sum(w * q, axis=1)
return self.l3(q_out)
It is difficult to catch up if you write it all at once, so I will repost it while dividing it into the following. First, convert the input image to a reward value. This is a normal CNN.
h = self.relu(self.conv1(x))
r = self.conv2(h)
Next is the VI module. By finding $ \ bar {Q} $ by the convolution layer conv3 and taking MAX for the motion channel (axis = 1), the best motion is selected at each position in the map. The reward value at that time is v. In the for sentence, the reward value estimated directly from the map and the propagated reward value are added together, and the same calculation as the first is performed.
q = self.conv3(r)
v = F.max(q, axis=1, keepdims=True)
for i in xrange(self.k - 1):
q = self.conv3(r) + self.conv3b(v)
v = F.max(q, axis=1, keepdims=True)
The Attention part that reduces the number of parameters by using only the part close to your position from the obtained reward map is as follows. First, add r and v by using $ \ hat {Q} $, which outputs the reward value for each action as a reward map. Then, for each piece of data in the batch, retrieve the number on the map that corresponds to your location. It's a little tricky because you can't do Fancy Index-like things with chainer, but prepare a matrix w with 1 in the position you want to retrieve and 0 in other places, and erase unnecessary elements by taking the product for each element. , The prescribed reward value is obtained by degenerating.
q = self.conv3(r) + self.conv3b(v)
t = s2 * q.data.shape[3] + s1
q = F.reshape(q, (q.data.shape[0], q.data.shape[1], -1))
q = F.rollaxis(q, 2, 1)
t_data_cpu = chainer.cuda.to_cpu(t.data)
w = np.zeros(q.data.shape, dtype=np.float32)
w[six.moves.range(t_data_cpu.size), t_data_cpu] = 1.0
if isinstance(q.data, chainer.cuda.ndarray):
w = chainer.cuda.to_gpu(w)
w = chainer.Variable(w, volatile=not self.train)
q_out = F.sum(w * q, axis=1)
Finally, the reward is converted into an action and output.
return self.l3(q_out)
Next, the dataset class (this code corresponds to chainer 1.10 or later)
class MapData(chainer.dataset.DatasetMixin):
def __init__(self, im, value, state, label):
self.im = np.concatenate(
(np.expand_dims(im, 1), np.expand_dims(value,1)),
axis=1).astype(dtype=np.float32)
self.s1, self.s2 = np.split(state, [1], axis=1)
self.s1 = np.reshape(self.s1, self.s1.shape[0])
self.s2 = np.reshape(self.s2, self.s2.shape[0])
self.t = label
def __len__(self):
return len(self.im)
def get_example(self, i):
return self.im[i], self.s1[i], self.s2[i], self.t[i]
The rest is almost the same as the CIFAR-10 sample. Including data generation, I will upload it to github soon. ~~ Uploaded.
Experimental result
Now, it's an experiment. The experiment was tried with the same parameters as in this paper. The number of data is 5000 for each type of map, 7 types of start are randomly decided for the map, and only 1 type of goal is for the map. The number of goals is small because it seems that a lot of calculation time is required to calculate the correct answer data. Experiments were conducted using 1/5 of the 5000 types as test data. The experiment is conducted on AWS, and it takes about several hours with 30 epochs. I didn't understand why it was displayed as 14 hours at the beginning of the sentence, but if I added cudnn separately, it could be executed in a few hours.
First, test case 1 is shown. The wall is black and the range of movement is white. The blue dot at the bottom is the start, and the light blue dot at the top is the goal. The recognized route is displayed in yellow. Even if there is a block that blocks it on the way, you can see that it detours properly and reaches the goal.

The following is the estimated reward map. You can see that the reward for the wall area is down. On the other hand, even in a large area, the reward seems to be higher in the area far from the wall.
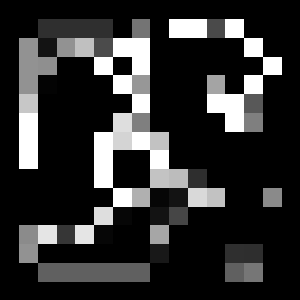
Finally, there is a diagram of future rewards output by the VI module. You can see that the reward near the goal is high. When choosing a route, you can reach the goal by going to the higher reward.

Next is test case 2. It doesn't change much, so I'll explain it briefly. This is a course that needs to be detoured a little larger, but it seems that the route can be recognized properly.

It seems that you can recognize both the reward map and the future reward map properly.


Summary
I wanted to do a little more quantitative experiment, but I've run out of time, so I'm done with this for the time being. As for the impression, it is a word that VIN is really amazing. Even though it is the first map I see, the route can be estimated properly! I can't say how big the problem can be scaled at this point, but I found it to be a very interesting technique. Also, I'm glad that it went well with one shot.
Chainer is still easy to use! However, in order to deal with special cases, I would like you to expand the Fancy Index a little more or automatically differentiate it.
By the way, the remaining questions are the following two points.
- Although the training data is only the shortest path, we were able to learn rewards for unlearned areas such as walls.
- Because it was adjusted to the value iteration, it was possible to learn even though VIM did not include a non-linear activation function. I feel that these are indispensable conditions for normal deep learning, but for some reason it was very strange that it worked.
By the way, it seems that the version that the author implements based on Theano is also up on github.
Recommended Posts