Table scraping with Beautiful Soup
Introduction
HTML tables can be scraped in a few lines using pandas' pd.read_html (), but this time I would like to show you how to scrape without using read_html ().
Preparation
Install Beautiful Soup. (This time, we will also use pandas to create a data frame, so install it as appropriate.)
$ pip install beautifulsoup4 # or conda install
policy
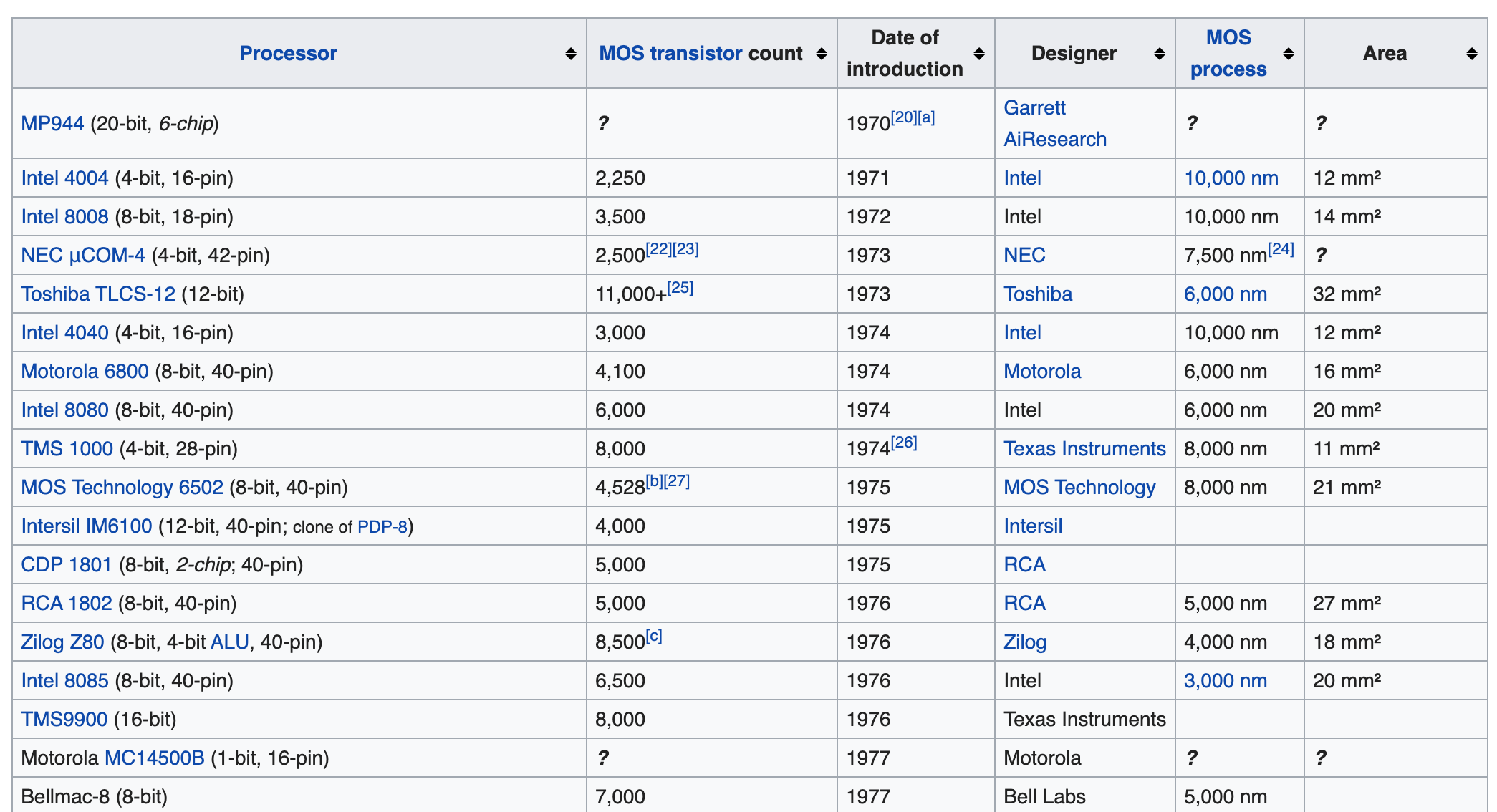
This time, as an example, let's get the following list of CPUs from this wikipedia page.
reference
Here, for reference, I would like to show the method when using the super-easy method pd.read_html ().
import pandas as pd
url = 'https://en.wikipedia.org/wiki/Transistor_count' #Target web page url
dfs = pd.read_html(url) #If the web page has multiple tables, they will be stored in dfs in list format
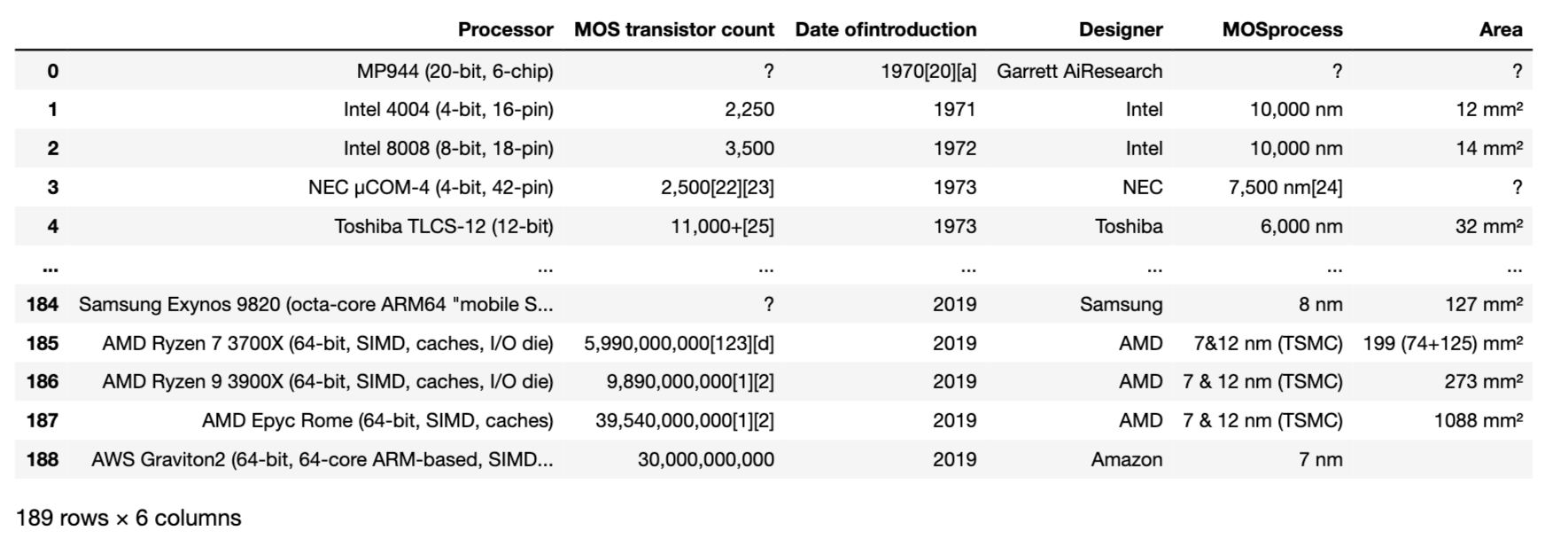
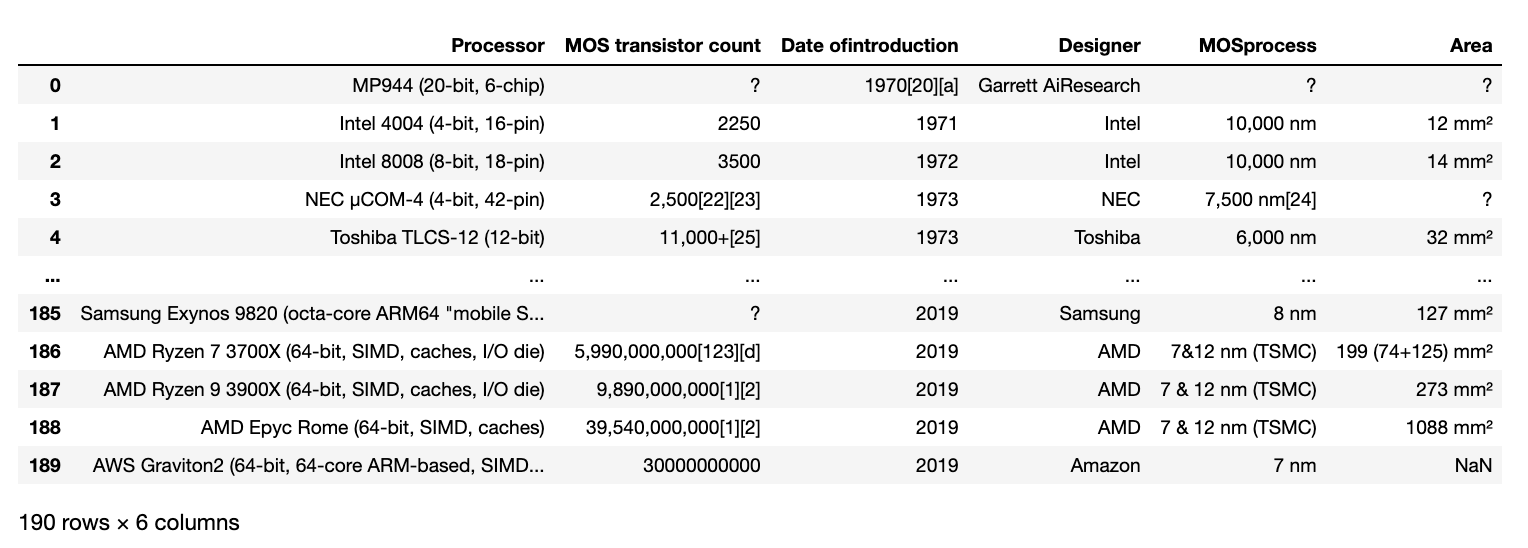
This time, it seems that the target table is stored in the first index of dfs, so let's output dfs [1](dfs [0] stores a table of another class).
dfs[1]
The output result looks like the image below, and you can certainly scrape it.
Overview
Before scraping a table with BeautifulSoup, let's take a look at the web page to which it is scraped. Let's jump to the wikipedia page from the link shown earlier and open the developer tools (in the case of chrome, you can display it by right-clicking on the table ⇒ inspect. You can also select option + command + I). Looking at the html source of the page with the developer tools, the target table is under the \
| (table cell data) You can see that it has a hierarchical structure (not visible in the image below, but there is a \ | tag in the hierarchy below \ at the same level as the \ |
|---|
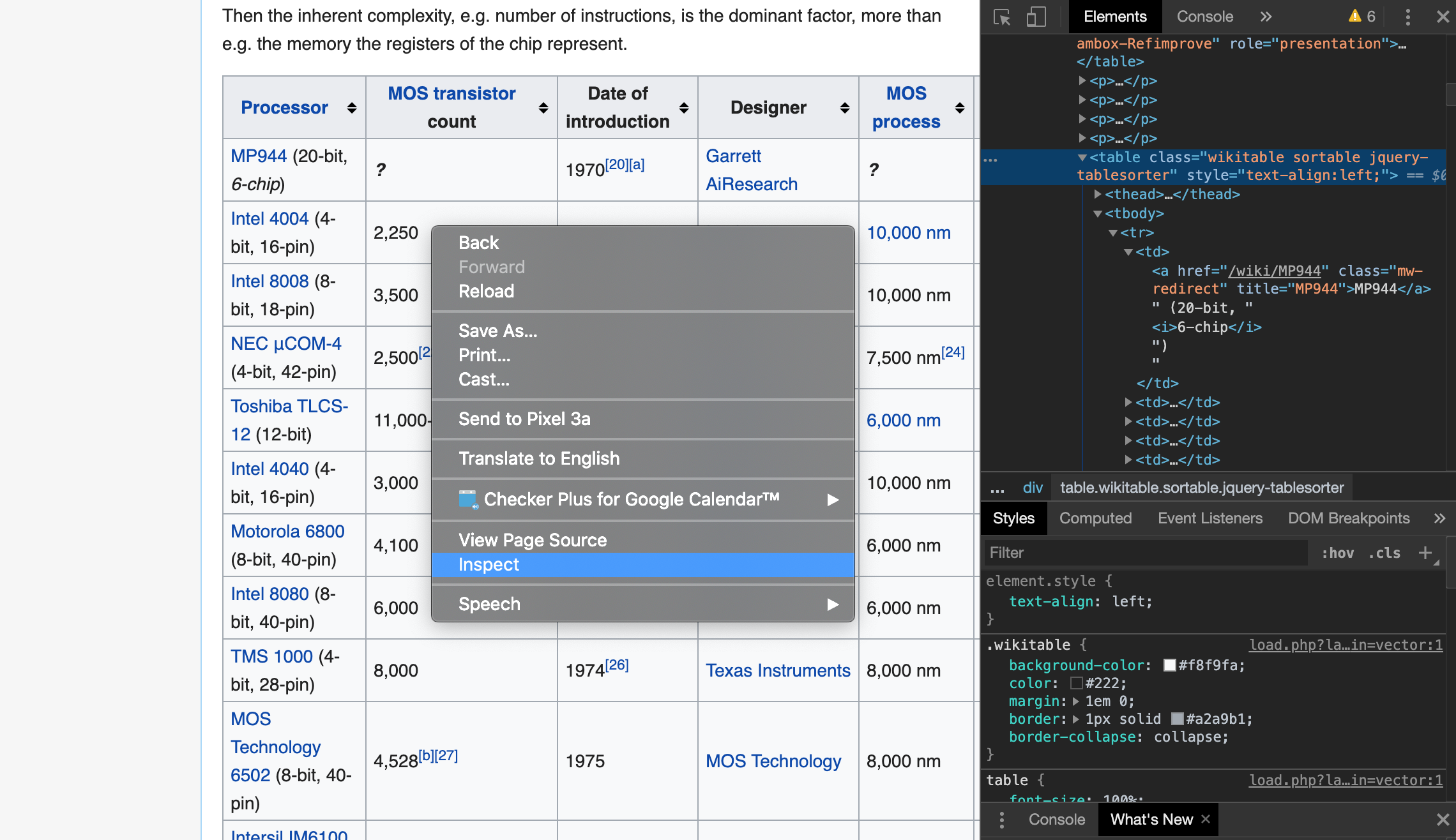
| tags inside the \ |
|---|
| tag hierarchy inside the \ |
tags that are the header components from the 0th row of the table, and extracts only the text component (v.text).
The result is as follows, but \ n indicating a line break is an obstacle.
|